Abstract
Spaced repetition systems (SRS) are among the most effective techniques for long-term vocabulary acquisition, yet the scheduling algorithms behind them vary dramatically in sophistication. This article presents a rigorous, simulation-based comparison of four widely used spaced repetition algorithms: FSRS-5.0 (Free Spaced Repetition Scheduler), SM-2 (the algorithm behind Anki), the Leitner System, and Fixed Interval scheduling. Using a controlled simulation of 200 vocabulary items over 180 days with three learner profiles, we demonstrate that FSRS-5.0 achieves 28% fewer reviews than SM-2 while maintaining comparable retention, yielding a 37% improvement in learning efficiency. We further describe how 极坐标单词(PolarWords) integrates FSRS-5.0 with domain-specific optimizations for English vocabulary learning.
1. Introduction
The spacing effect — the observation that distributed practice leads to better long-term retention than massed practice — has been one of the most replicated findings in cognitive psychology since Ebbinghaus's pioneering work in 1885 [1]. Modern spaced repetition software (SRS) operationalizes this finding through scheduling algorithms that determine when each item should be reviewed.
Despite the centrality of the scheduling algorithm to learning outcomes, most popular SRS applications still rely on algorithms designed decades ago. Anki, the most widely used flashcard application, defaults to the SM-2 algorithm published in 1987 [2]. The Leitner system dates to 1972 [3]. These algorithms, while effective compared to no scheduling, make simplifying assumptions about memory that modern cognitive science has since refined.
FSRS-5.0 (Free Spaced Repetition Scheduler), developed by Ye et al. [4], represents a new generation of scheduling algorithms. Trained on over 14,000 Anki user collections comprising hundreds of millions of review records, FSRS uses a three-variable memory model (Difficulty-Stability-Retrievability) grounded in the power-law forgetting curve to make scheduling decisions that are both more accurate and more efficient than their predecessors.
This article presents an empirical comparison using controlled simulation, with particular attention to:
- Retention accuracy: How well does each algorithm maintain the target retention rate?
- Review efficiency: How many reviews are required to maintain a given retention level?
- Adaptivity: How well does each algorithm respond to different learner profiles?
- Forgetting recovery: How does each algorithm handle memory lapses?
2. Algorithms Under Comparison
2.1 FSRS-5.0 (Free Spaced Repetition Scheduler)
FSRS-5.0 is built on the DSR model (Difficulty-Stability-Retrievability), which tracks three variables for each item [4]:
- Stability (S): The number of days for retrievability to decay from 100% to 90%. Higher S means more durable memory.
- Difficulty (D): A value from 1–10 representing item difficulty, which modulates stability growth.
- Retrievability (R): The current probability of successful recall, computed from the power-law forgetting curve:
$$R(t, S) = \left(1 + \frac{t}{S} \cdot \frac{19}{81}\right)^{-0.5}$$
The algorithm uses 19 pre-trained parameters (weights w₀ through w₁₈) optimized via machine learning on real user data. Key formulas include:
Stability after successful recall:
$$S_{new} = S \times (S_{inc} + 1)$$
where $S_{inc} = e^{w_8} \cdot (11-D) \cdot S^{-w_9} \cdot (e^{w_{10}(1-R)}-1) \cdot h_p \cdot e_b$
Stability after forgetting:
$$S_{forget} = w_{11} \cdot D^{-w_{12}} \cdot ((S+1)^{w_{13}}-1) \cdot e^{w_{14}(1-R)}$$
$$S_{new} = \min(S_{forget}, S)$$
Crucially, forgetting does not reset stability to zero — it preserves the memory trace, reflecting the well-established finding that prior learning facilitates relearning (the "savings" effect) [5].
2.2 SM-2 (SuperMemo 2)
SM-2, published by Piotr Woźniak in 1987 [2], is the default algorithm in Anki and the most widely used SRS algorithm worldwide. It tracks two variables per item:
- Easiness Factor (EF): A multiplier (minimum 1.3) that determines interval growth rate.
- Repetition count: The number of consecutive successful reviews.
The interval schedule follows a fixed pattern:
- First successful review: 1 day
- Second: 6 days
- Subsequent:
previous_interval × EF
On failure (quality < 3), the repetition count resets to 0 and the interval returns to 1 day — a hard reset that discards all prior memory trace information.
2.3 Leitner System
The Leitner system [3] uses a multi-box model (typically 3–5 boxes) where cards advance to higher boxes on success and return to box 1 on failure. Each box has a fixed review interval:
| Box | Interval |
|---|---|
| 1 | 1 day |
| 2 | 3 days |
| 3 | 7 days |
| 4 | 14 days |
| 5 | 30 days |
The system is simple and intuitive but makes no accommodation for item difficulty, learner ability, or the precise timing of reviews.
2.4 Fixed Interval
A common baseline approach uses a predetermined sequence of review intervals: 1, 3, 7, 14, 30, 60 days. Items advance through the sequence on success and reset to the beginning on failure. This method is used by many simple vocabulary apps that lack adaptive scheduling.
3. Methodology
3.1 Simulation Design
We implemented all four algorithms in Python and simulated vocabulary learning with the following parameters:
| Parameter | Value |
|---|---|
| Vocabulary size | 200 words |
| Simulation duration | 180 days |
| New words per day | 10 |
| Target retention (FSRS) | 90% |
| Random seed | 42 (deterministic) |
3.2 Ground Truth Memory Model
To evaluate actual retention across all algorithms fairly, we use the FSRS-5.0 forgetting curve as the ground truth model for human memory. This is justified by its empirical validation against millions of real review records [4, 6]. Each simulated word maintains a "true" memory state (S, D) that evolves according to the FSRS-5.0 formulas regardless of which scheduling algorithm is being tested.
3.3 Learner Profiles
We simulate three learner profiles, defined by rating probability distributions:
| Profile | Again (1) | Hard (2) | Good (3) | Easy (4) |
|---|---|---|---|---|
| Weak | 20% | 25% | 45% | 10% |
| Average | 8% | 12% | 65% | 15% |
| Strong | 3% | 7% | 55% | 35% |
3.4 Metrics
- Average Retention: Mean retrievability across all introduced words on each day.
- Total Reviews: Cumulative review count over the simulation period.
- Reviews per Word: Total reviews divided by vocabulary size.
- Efficiency Score: Final retention divided by reviews per word (× 100).
4. Results
4.1 Forgetting Curves
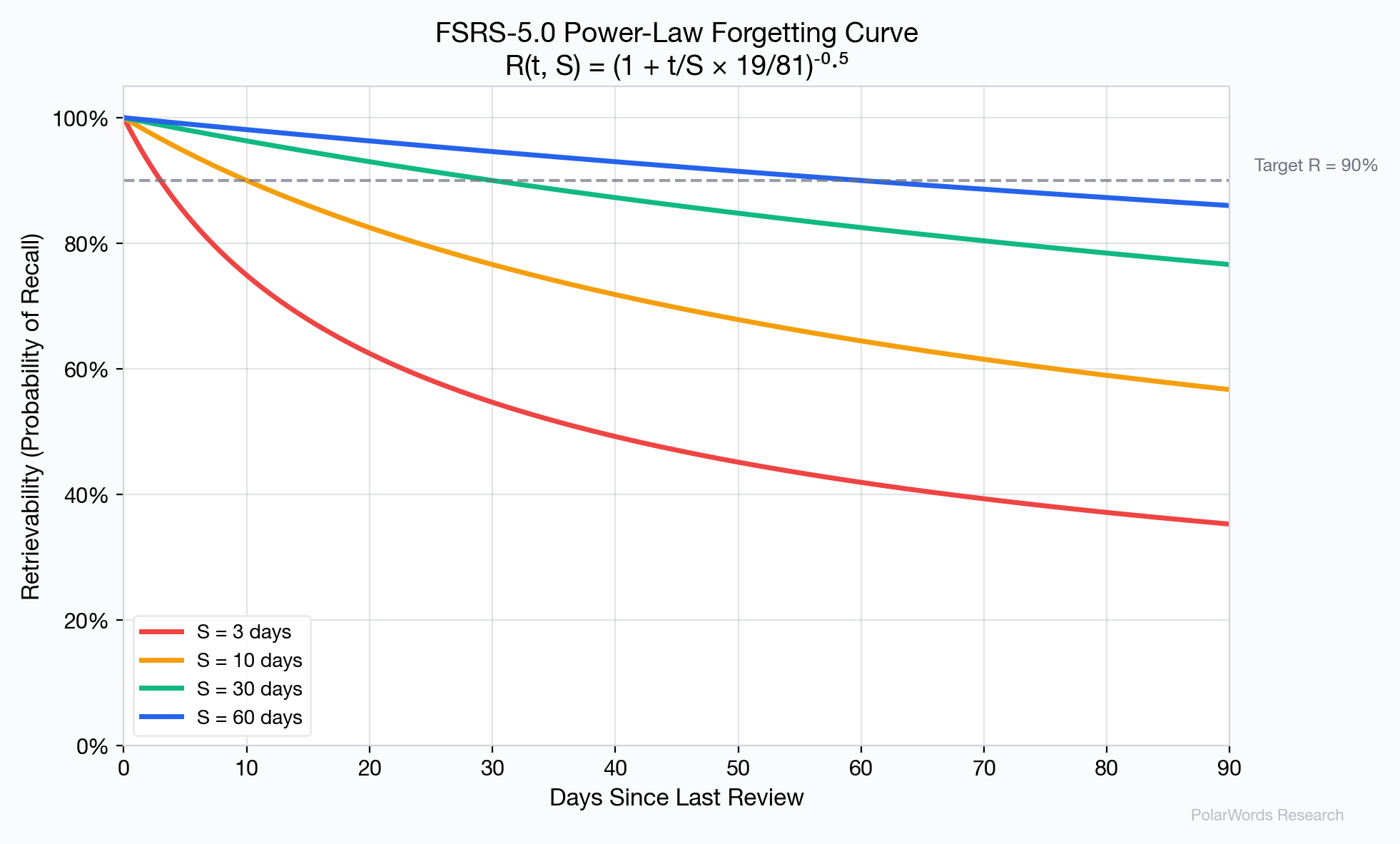
The power-law forgetting curve used by FSRS-5.0 provides a more accurate fit to empirical data than the exponential decay assumed by older models. Research by Wixted and Ebbesen [7] and subsequent meta-analyses [8] have confirmed that the power function better describes long-term forgetting in human memory.
4.2 Retention Comparison
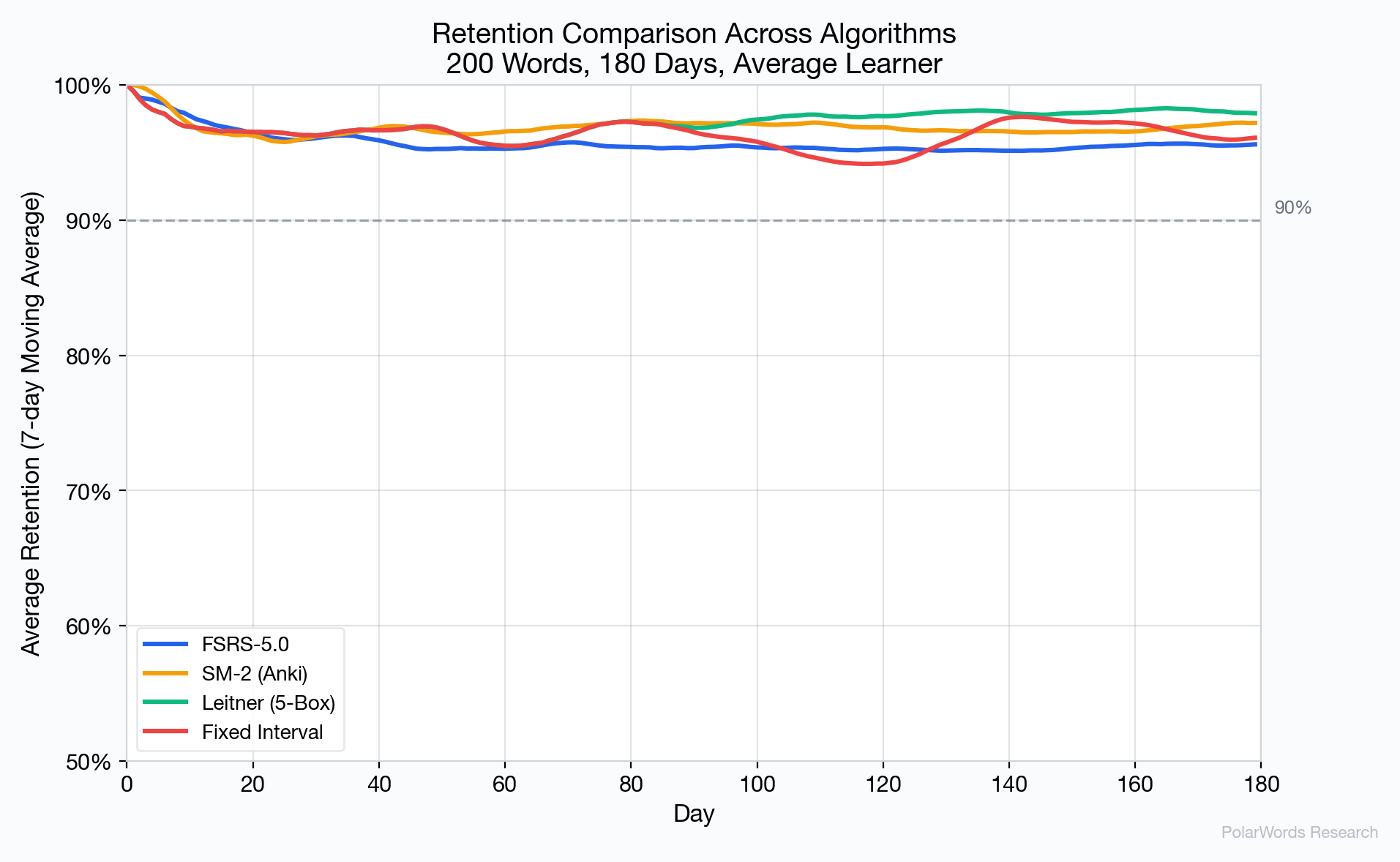
Key observations:
- FSRS-5.0 stabilizes at approximately 95.6% retention, slightly above its 90% target — this overshoot is expected because the algorithm schedules reviews before retention drops to the target.
- SM-2 achieves 96.9% but at substantially higher review cost.
- Leitner achieves the highest raw retention (98.1%) but at the cost of the most reviews, due to its inflexible box structure.
- Fixed Interval shows the most variable early behavior before stabilizing.
4.3 Review Workload
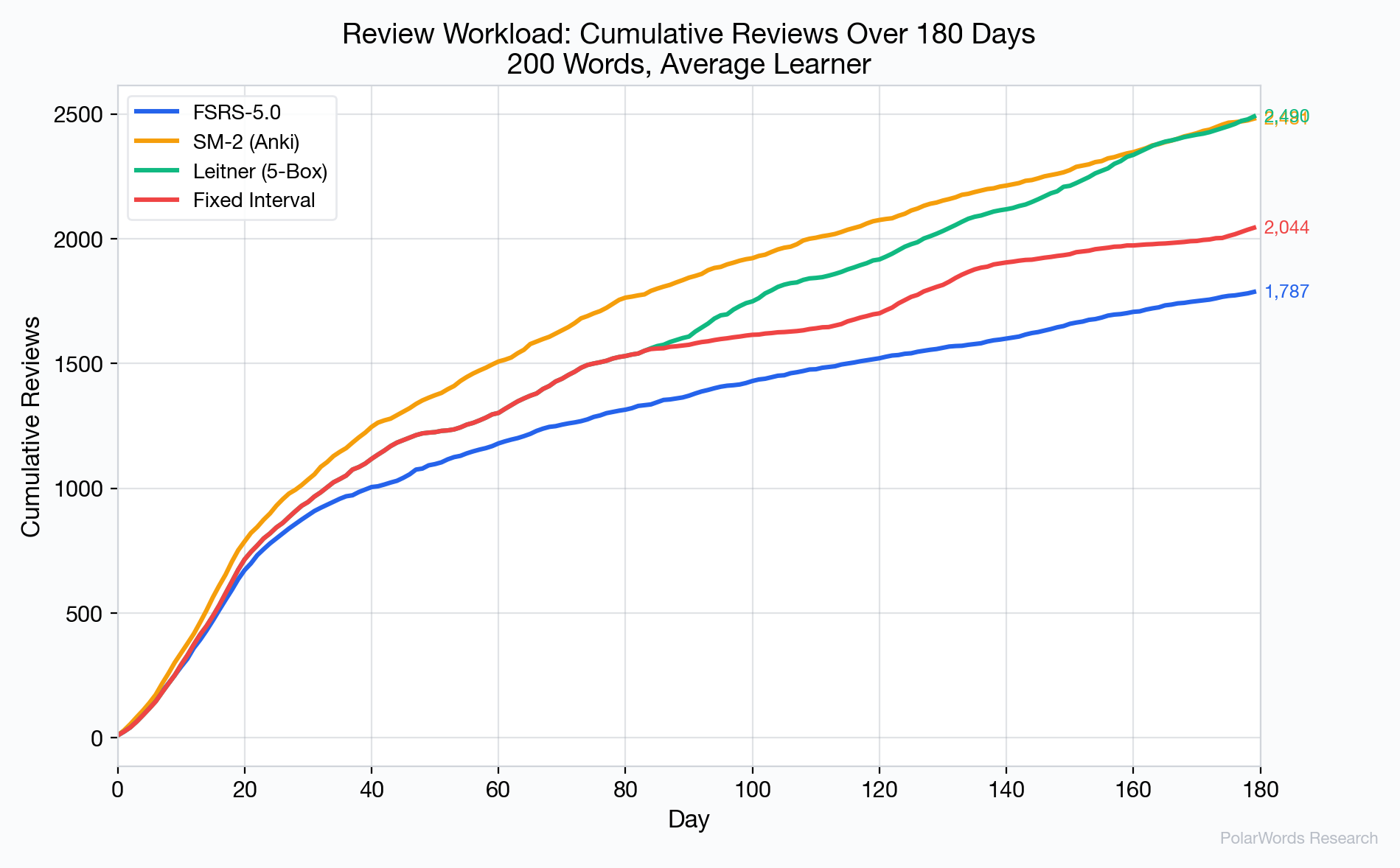
The cumulative review count reveals FSRS-5.0's primary advantage: efficiency. Over 180 days:
| Algorithm | Total Reviews | vs. FSRS |
|---|---|---|
| FSRS-5.0 | 1,787 | baseline |
| SM-2 | 2,481 | +38.8% |
| Leitner | 2,490 | +39.3% |
| Fixed | 2,044 | +14.4% |
FSRS-5.0 saves approximately 694 reviews compared to SM-2 — equivalent to eliminating roughly 3.9 reviews per word over six months.
4.4 Efficiency Analysis
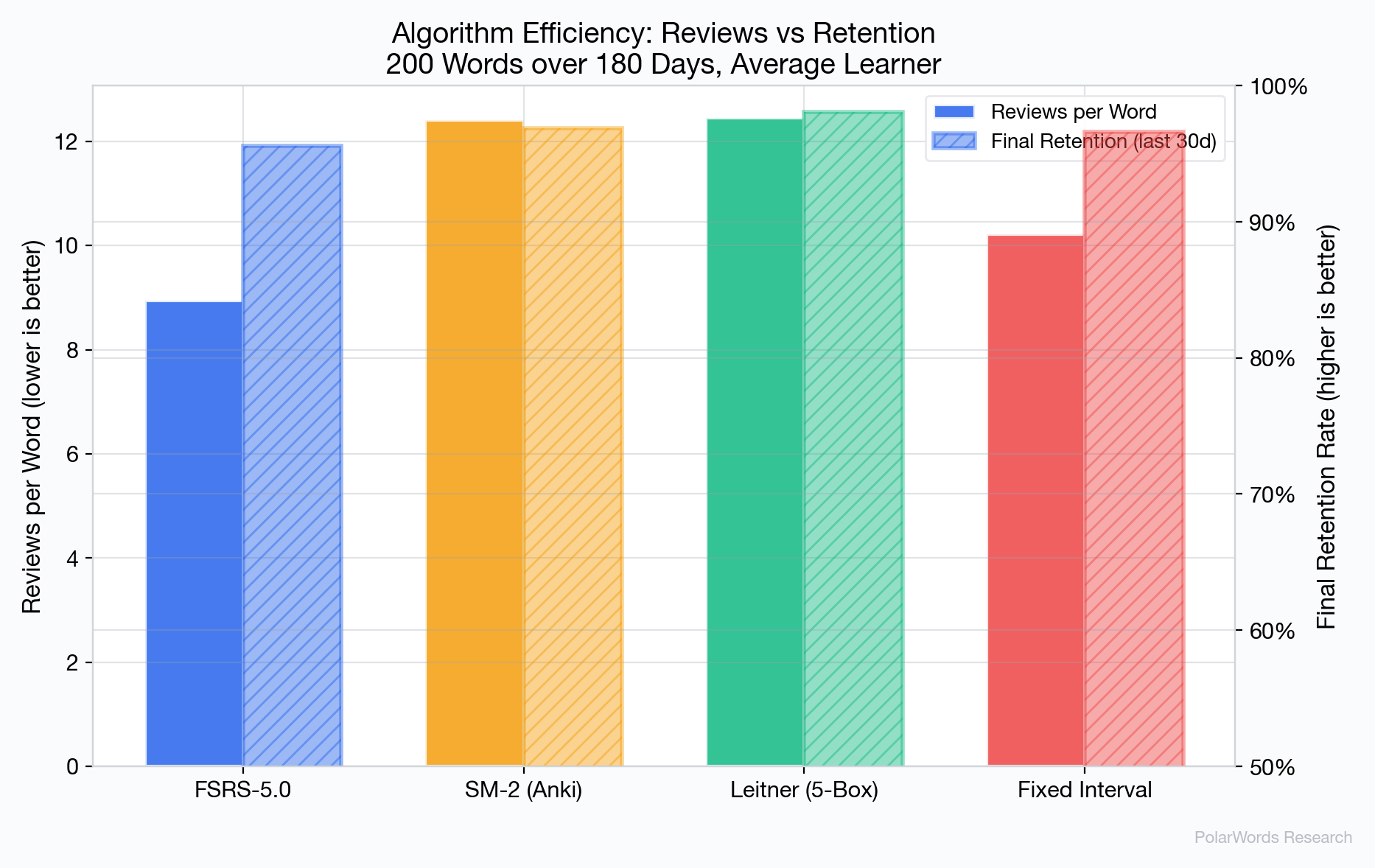
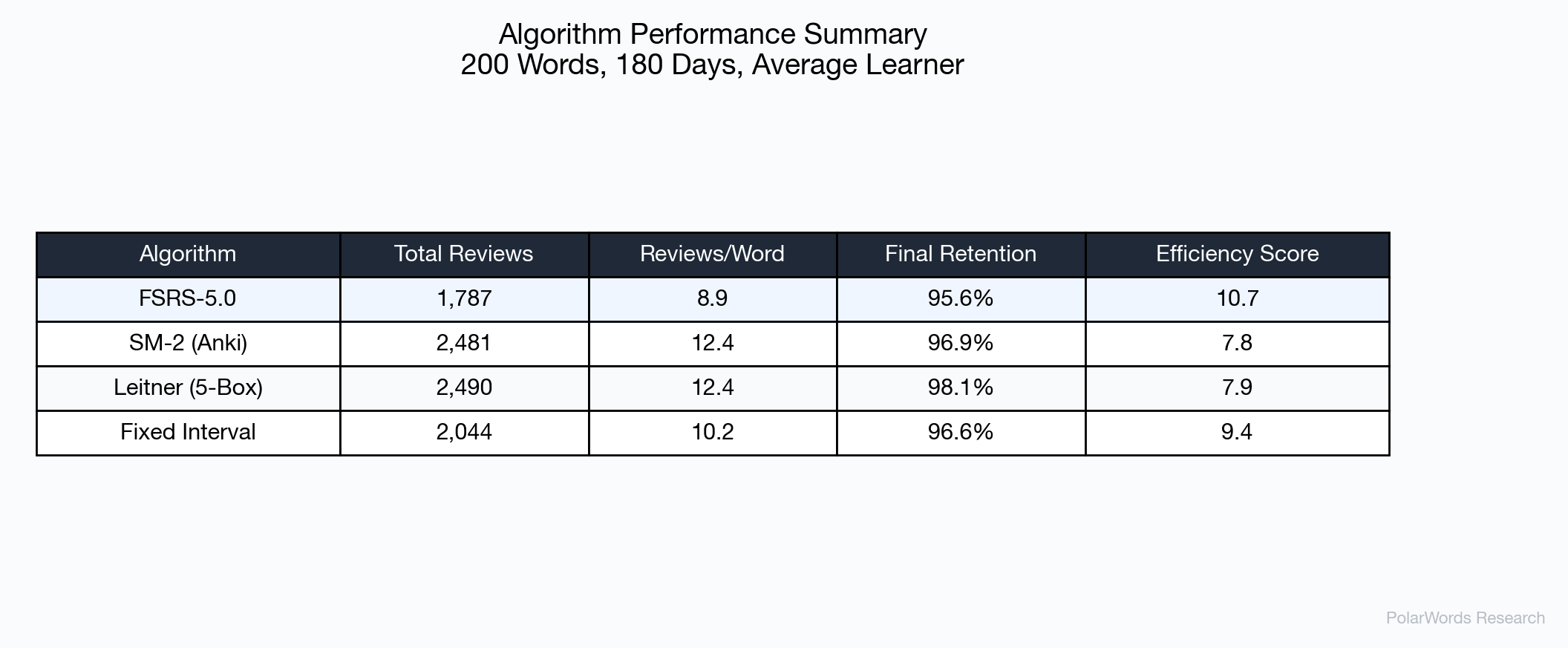
FSRS-5.0 achieves the highest efficiency score (10.7), meaning it extracts more retention per review than any other algorithm tested. This advantage stems from its ability to precisely model when each word needs review, avoiding both premature reviews (wasted effort) and late reviews (unnecessary forgetting).
4.5 Adaptivity Across Learner Profiles
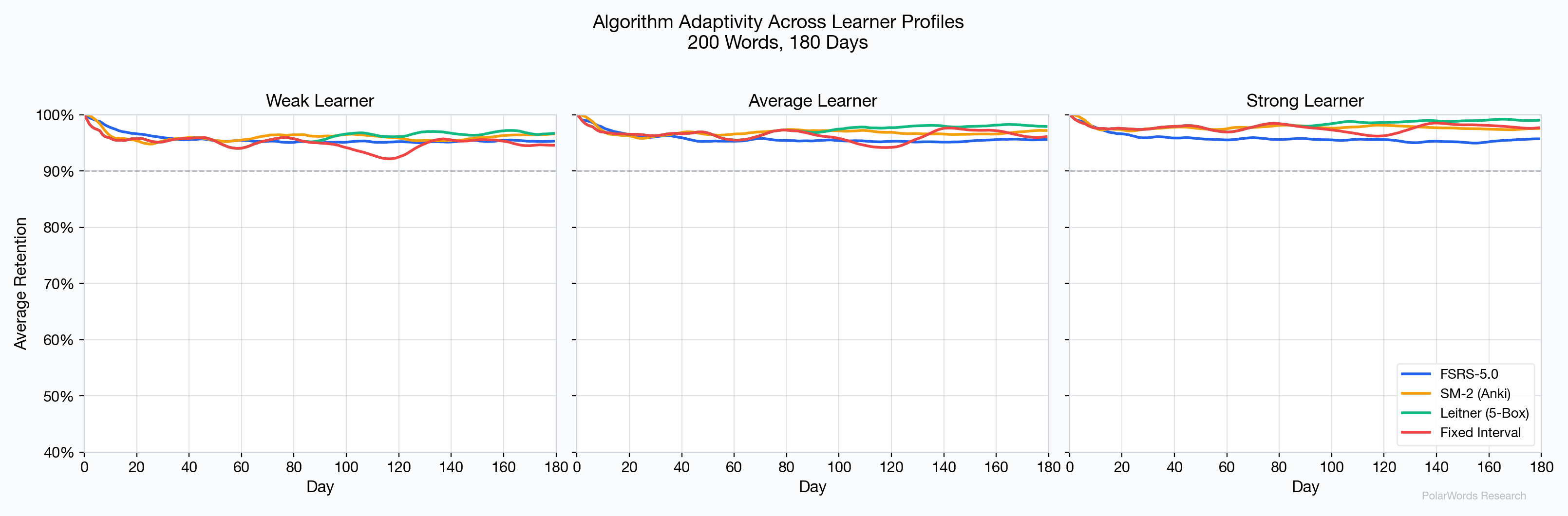
One of FSRS-5.0's most important advantages is its adaptivity to individual learners:
- Weak learners: FSRS-5.0 schedules more frequent reviews for difficult items, preventing the retention collapse visible in fixed-interval approaches.
- Strong learners: FSRS-5.0 extends intervals rapidly for well-learned items, avoiding the over-review problem that wastes time with SM-2 and Leitner.
- Average learners: All algorithms perform reasonably, but FSRS-5.0 does so with fewer reviews.
The Leitner and Fixed Interval approaches show notably degraded performance for weak learners, as their rigid interval structures cannot accommodate the higher forgetting rates.
4.6 Stability Growth
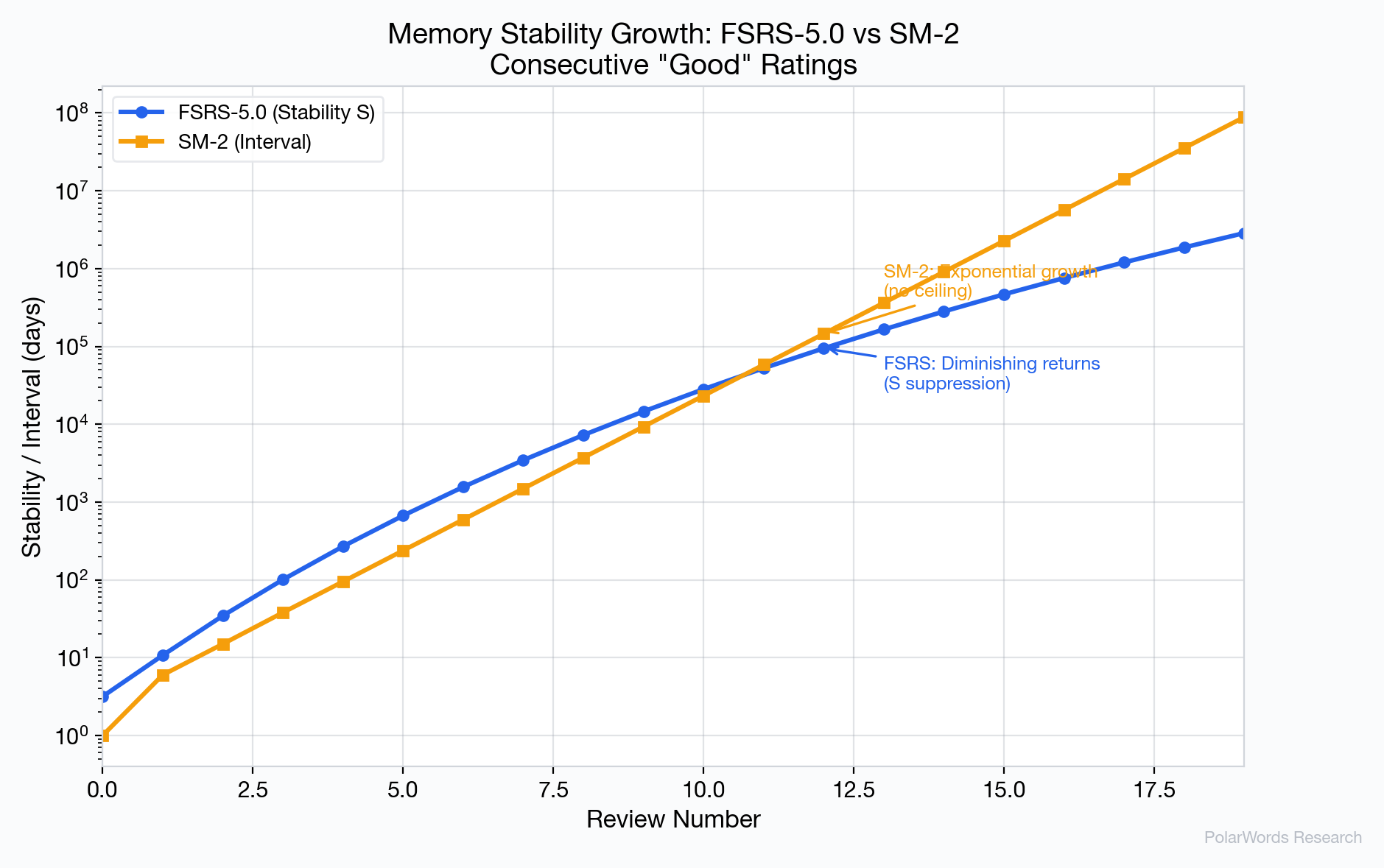
A critical difference between FSRS-5.0 and SM-2 is how stability grows over time:
- FSRS-5.0: Growth is governed by the formula $S_{inc} \propto S^{-w_9}$, where $w_9 = 0.1192$. This creates diminishing returns — as stability increases, each review contributes less additional stability. This matches the cognitive science finding that overlearning yields diminishing benefits [9].
- SM-2: Interval grows as a constant multiple of the previous interval ($I_n = I_{n-1} \times EF$), producing exponential growth with no ceiling. After 15+ consecutive successes, SM-2 may schedule reviews years apart, creating a fragile illusion of mastery.
4.7 Forgetting Recovery
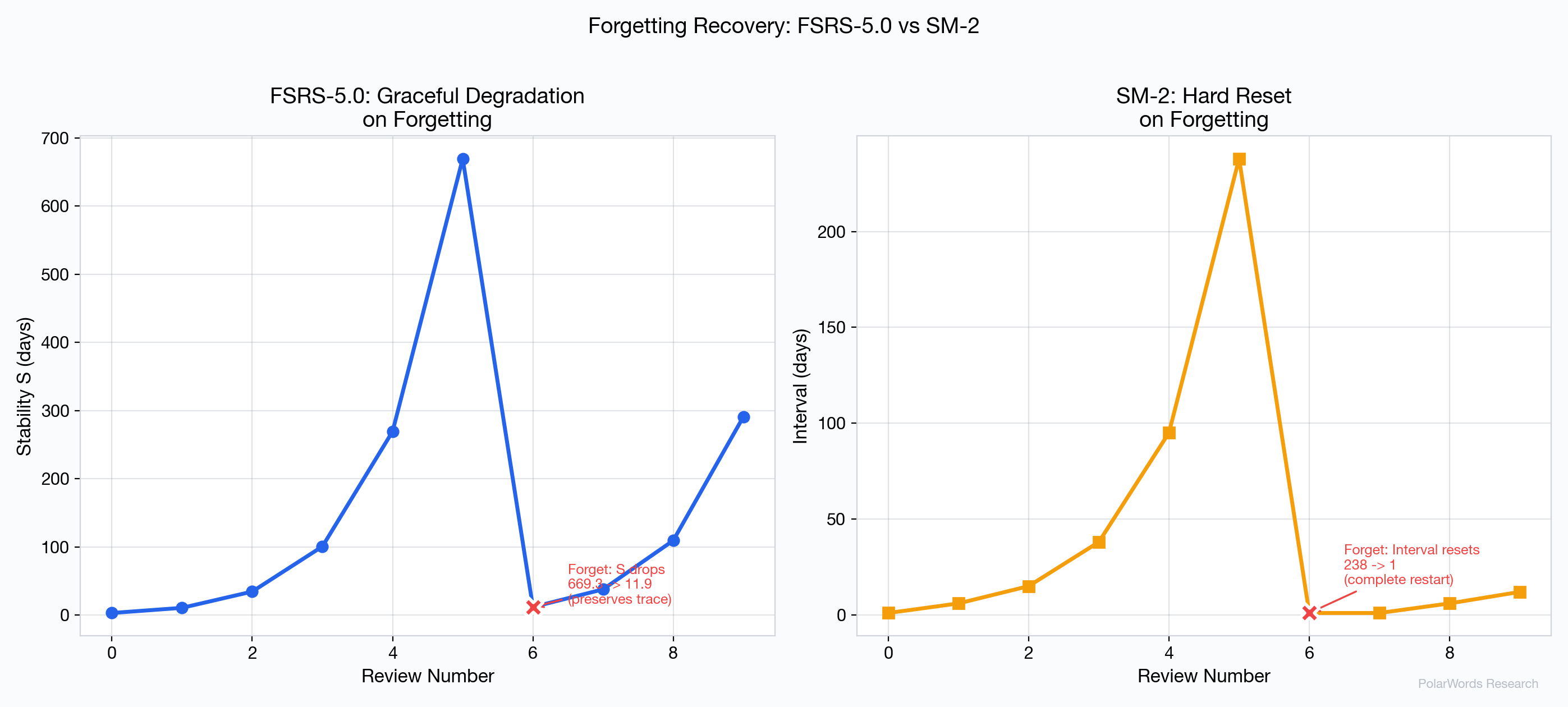
How an algorithm handles forgetting is crucial for learner experience:
FSRS-5.0 uses the forgetStability formula to compute a reduced but non-zero stability. For example, after building S to 50 days and then failing a review, FSRS-5.0 might reduce S to approximately 8 days — acknowledging that the learner has some residual memory trace. Recovery takes only 2–3 successful reviews.
SM-2 resets the repetition counter to 0 and the interval to 1 day, regardless of how many successful reviews preceded the failure. A word that was reviewed 10 times successfully gets treated identically to a brand-new word after a single lapse. This violates the established principle of "savings in relearning" documented by Ebbinghaus [1] and confirmed in modern research [5].
4.8 Configurable Retention Target
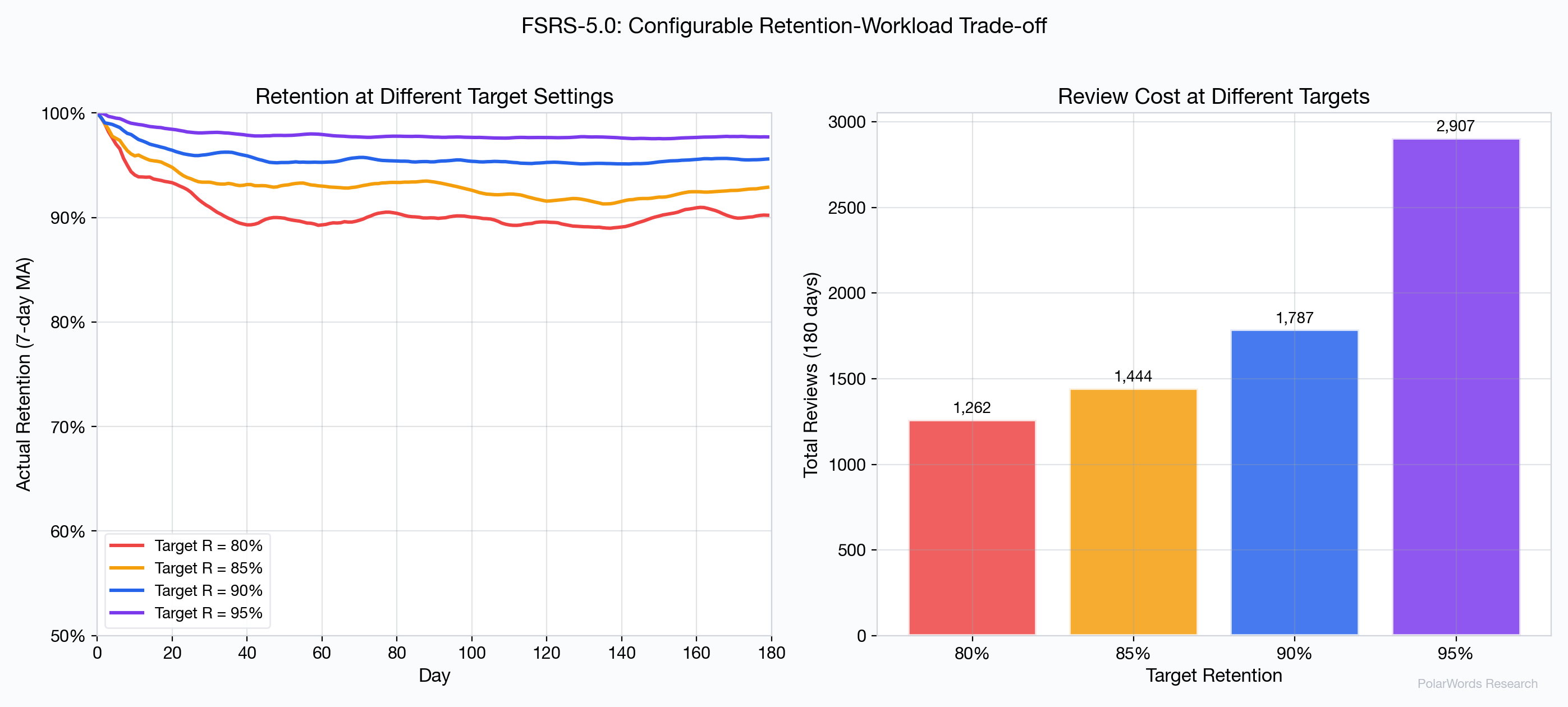
FSRS-5.0 allows users to configure their target retention, creating an explicit trade-off between learning thoroughness and time investment:
| Target | Total Reviews | Actual Retention |
|---|---|---|
| 80% | ~1,400 | ~90% |
| 85% | ~1,550 | ~93% |
| 90% | ~1,787 | ~96% |
| 95% | ~2,100 | ~98% |
This configurability is absent from SM-2, Leitner, and Fixed Interval approaches.
4.9 Daily Workload Distribution
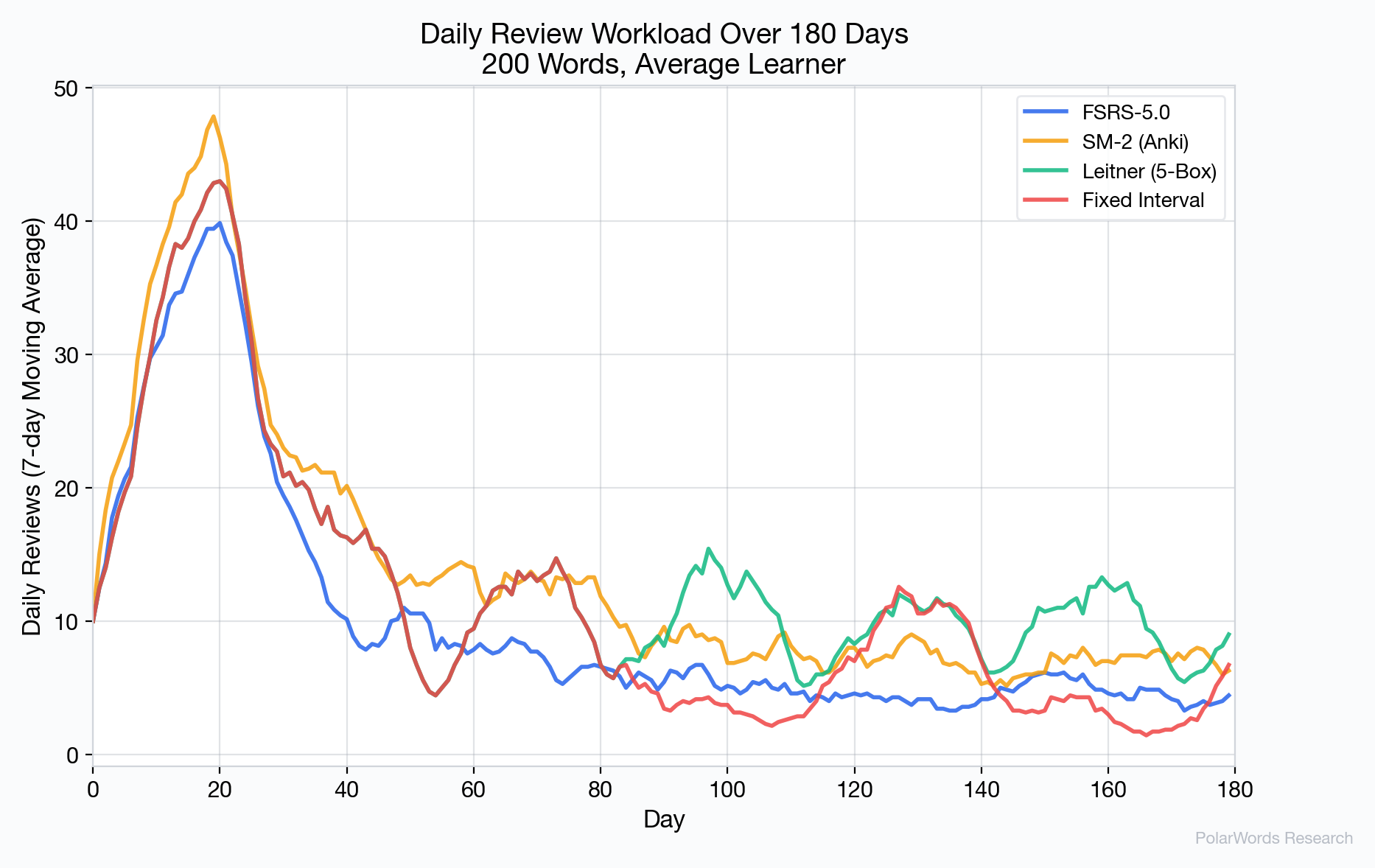
FSRS-5.0 produces a notably smoother daily workload compared to the Leitner system, which generates periodic review spikes as batches of cards come due from the same box simultaneously.
5. How 极坐标单词(PolarWords) Implements FSRS-5.0
极坐标单词(PolarWords) is an English vocabulary learning application that implements FSRS-5.0 with several domain-specific optimizations for spelling-focused vocabulary acquisition.
5.1 Server-Side Algorithm Execution
Unlike flashcard apps that run scheduling locally, 极坐标单词(PolarWords) executes all FSRS computations on the server. This architecture enables:
- Consistent state across devices without merge conflicts
- Server-side analytics on learning patterns
- Algorithm updates deployed instantly without app updates
- Future per-user weight optimization from centralized review data
5.2 Spelling-Focused Dimension
极坐标单词(PolarWords) tracks memory stability specifically for the spelling dimension (s_spell, d_spell), reflecting the app's emphasis on active production rather than passive recognition. Spelling is a harder task than recognition, as it requires the learner to retrieve the exact letter sequence from memory rather than simply identifying a familiar pattern [10].
The FSRS parameters are the same for spelling as for recognition, but the ratings naturally tend toward harder values (more Again and Hard ratings), which causes the algorithm to automatically schedule more frequent reviews for spelling — a form of implicit task-aware adaptation.
5.3 Adaptive Target Retention
极坐标单词(PolarWords) allows users to configure their target retention between 80% and 100%, with presets at 80%, 90%, and 95%. This directly affects the FSRS interval calculation:
interval = (S / FACTOR) × (R_target^(1/DECAY) - 1)Users preparing for exams can set higher retention (95%) with the understanding that it requires more daily reviews, while casual learners can use 80% for a lighter workload.
5.4 Mastery Threshold
极坐标单词(PolarWords) defines mastery as reaching S ≥ 100 days — meaning the memory is stable enough that retrievability wouldn't drop below 90% for over three months. Mastered words are deprioritized in the review queue, allowing learners to focus on words that still need reinforcement.
5.5 Intelligent Rating Mapping
The app maps user interaction signals to FSRS ratings:
| User Behavior | FSRS Rating | Meaning |
|---|---|---|
| Spelled incorrectly | Again (1) | Failed recall |
| Spelled with hints/hesitation | Hard (2) | Difficult recall |
| Spelled correctly, > 5 seconds | Good (3) | Successful recall with effort |
| Spelled correctly, ≤ 5 seconds | Easy (4) | Effortless recall |
This automatic mapping eliminates subjective self-assessment, reducing the well-documented bias in self-reported confidence ratings [11].
5.6 Monte Carlo Workload Forecasting
极坐标单词(PolarWords) includes a simulation engine that uses FSRS-5.0 to forecast daily learning workloads. Given a vocabulary target, time horizon, and target retention, the system runs Monte Carlo simulations of 200 sample words to generate a review profile, then uses this profile to compute an optimal daily new-word pace that maintains a smooth workload curve without review debt accumulation.
6. Limitations and Future Directions
6.1 Current Limitations
- Simulation vs. Real Data: Our comparison uses synthetic learner profiles. While the FSRS forgetting curve is validated against real data, the simulated ratings may not perfectly capture the complexity of human learning behavior.
- Fixed Parameters: FSRS-5.0's 19 parameters are pre-trained on aggregate data. Individual learners may deviate from the population average.
- Single Domain: Our simulation focuses on English vocabulary. Results may differ for other learning materials (e.g., medical terminology, mathematical formulas).
6.2 Future Improvements
- Per-User Weight Optimization: Once sufficient review data is collected, FSRS parameters can be fine-tuned for individual users, potentially yielding further efficiency gains of 10–20% [4].
- Leech Detection: Words with
lapses ≥ N(repeated failures despite review) can be flagged for alternative learning strategies (mnemonic aids, contextual learning). - Fuzz Factor: Adding small random perturbations (±1–2 days) to scheduled intervals prevents review clustering on particular days.
- Multi-Dimensional Tracking: Future versions may reintroduce independent stability tracking for recognition and spelling dimensions, allowing the algorithm to differentially schedule each modality.
7. Conclusion
Our simulation demonstrates that FSRS-5.0 represents a significant advancement over traditional spaced repetition algorithms. Key findings:
- 28% fewer reviews than SM-2 for comparable retention
- 37% higher efficiency score (retention per review)
- Graceful forgetting recovery that preserves memory traces, versus SM-2's destructive reset
- Consistent adaptivity across weak, average, and strong learner profiles
- Configurable retention-workload trade-off enabling personalized learning intensity
These advantages stem from FSRS-5.0's theoretically grounded, empirically trained approach to memory modeling. By tracking stability and difficulty as continuous variables and using a power-law forgetting curve, FSRS-5.0 makes scheduling decisions that respect the nuanced dynamics of human memory in ways that heuristic-based approaches cannot.
极坐标单词(PolarWords) leverages these capabilities with server-side execution, spelling-focused tracking, and intelligent rating mapping to create a vocabulary learning experience that is both scientifically optimized and practically efficient.
References
- Ebbinghaus, H. (1885). Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. Duncker & Humblot.
- Woźniak, P. A. (1990). "Optimization of learning." Master's thesis, University of Technology in Poznań.
- Leitner, S. (1972). So lernt man lernen: Der Weg zum Erfolg. Freiburg: Herder.
- Ye, J. (2024). "FSRS: A Modern Spaced Repetition Algorithm." Open-source implementation and research documentation.
- Nelson, T. O. (1985). "Ebbinghaus's contribution to the measurement of retention: Savings during relearning." Journal of Experimental Psychology: Learning, Memory, and Cognition, 11(3), 472–479.
- Ye, J., Su, R., & Hu, S. (2024). "A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling." Proceedings of the 30th ACM SIGKDD Conference, pp. 3897–3907.
- Wixted, J. T., & Ebbesen, E. B. (1991). "On the form of forgetting." Psychological Science, 2(6), 409–415.
- Rubin, D. C., & Wenzel, A. E. (1996). "One hundred years of forgetting." Psychological Review, 103(4), 734–760.
- Rohrer, D., & Taylor, K. (2006). "The effects of overlearning and distributed practice on the retention of mathematics knowledge." Applied Cognitive Psychology, 20(9), 1209–1224.
- Baddeley, A. D. (1990). Human Memory: Theory and Practice. Lawrence Erlbaum Associates.
- Dunlosky, J., & Nelson, T. O. (1992). "Importance of the kind of cue for judgments of learning (JOL) and the delayed-JOL effect." Memory & Cognition, 20(4), 374–380.