摘要
间隔重复系统 (SRS) 是长期词汇习得中最有效的技术之一,但其背后的调度算法在复杂度和效果上差异巨大。本文通过严格的仿真对比,评估四种主流间隔重复算法:FSRS-5.0(Free Spaced Repetition Scheduler,自由间隔重复调度器)、SM-2(Anki 默认算法)、Leitner 系统(莱特纳卡片盒法)及固定间隔法。在200个词汇、180天的控制仿真中,我们证明 FSRS-5.0 相比 SM-2 减少28%的复习次数,同时保持相当的记忆保留率,学习效率提升37%。同时介绍了极坐标单词(PolarWords)如何将 FSRS-5.0 与英语词汇学习的特定优化相结合。
1. 引言
间隔效应——分散练习比集中练习带来更好的长期记忆保持——是自1885年艾宾浩斯开创性工作以来,认知心理学中被重复验证次数最多的发现之一 [1]。现代间隔重复软件通过调度算法将这一发现工程化,计算每个学习项目何时应被复习。
尽管调度算法对学习效果至关重要,大多数主流 SRS 应用仍然依赖几十年前设计的算法。全球使用最广泛的闪卡应用 Anki 默认使用1987年发表的 SM-2 算法 [2];Leitner 系统则可追溯至1972年 [3]。这些算法虽然比不做调度要好,但对记忆的建模做了过度简化,而现代认知科学已经提供了更精确的模型。
FSRS-5.0(Free Spaced Repetition Scheduler)由叶峻等人开发 [4],代表了新一代调度算法。该算法基于超过14,000个 Anki 用户合集、数亿条复习记录训练而成,使用三变量记忆模型(难度-稳定性-可提取性,DSR),以幂律遗忘曲线为基础做出比前辈算法更准确、更高效的调度决策。
本文通过控制仿真实验进行实证对比,重点关注:
- 保留率准确性:各算法维持目标保留率的效果如何?
- 复习效率:维持一定保留率水平需要多少复习次数?
- 适应性:各算法对不同学习者类型的响应如何?
- 遗忘恢复:各算法如何处理记忆衰退?
2. 算法概述
2.1 FSRS-5.0(自由间隔重复调度器)
FSRS-5.0 基于 DSR 模型(Difficulty-Stability-Retrievability),为每个学习项跟踪三个变量 [4]:
- 稳定性 (S):可提取性从100%衰减到90%所需的天数。S 越大,记忆越牢固。
- 难度 (D):1-10的数值,表示材料难度,调节稳定性的增长速度。
- 可提取性 (R):当前成功回忆的概率,由幂律遗忘曲线计算:
$$R(t, S) = \left(1 + \frac{t}{S} \cdot \frac{19}{81}\right)^{-0.5}$$
算法使用19个预训练参数(权重 w₀ 至 w₁₈),通过机器学习在真实用户数据上优化。核心公式包括:
成功回忆后的稳定性更新:
$$S_{new} = S \times (S_{inc} + 1)$$
其中 $S_{inc} = e^{w_8} \cdot (11-D) \cdot S^{-w_9} \cdot (e^{w_{10}(1-R)}-1) \cdot h_p \cdot e_b$
遗忘后的稳定性更新:
$$S_{forget} = w_{11} \cdot D^{-w_{12}} \cdot ((S+1)^{w_{13}}-1) \cdot e^{w_{14}(1-R)}$$
$$S_{new} = \min(S_{forget}, S)$$
关键设计:遗忘不会将稳定性重置为零——它保留了记忆痕迹,体现了"重新学习中的节省"这一已被充分证实的认知现象 [5]。
2.2 SM-2(SuperMemo 2)
SM-2 由 Piotr Woźniak 于1987年发表 [2],是 Anki 的默认算法,也是全球使用最广泛的 SRS 算法。每个学习项跟踪两个变量:
- 简易系数 (EF):决定间隔增长速率的乘数(最小值1.3)。
- 重复计数:连续成功复习的次数。
间隔遵循固定模式:
- 首次成功复习:1天
- 第二次:6天
- 此后:
前次间隔 × EF
失败时(质量 < 3),重复计数重置为0,间隔回到1天——这是一种硬重置,丢弃了所有先前的记忆痕迹信息。
2.3 Leitner 系统(莱特纳卡片盒法)
Leitner 系统 [3] 使用多层盒子模型(通常3-5个盒子),成功时卡片晋升到更高的盒子,失败时回到第1个盒子。每个盒子有固定的复习间隔:
| 盒子 | 间隔 |
|---|---|
| 1 | 1天 |
| 2 | 3天 |
| 3 | 7天 |
| 4 | 14天 |
| 5 | 30天 |
该系统简单直观,但不考虑材料难度、学习者能力或复习的精确时间。
2.4 固定间隔法
一种常见的基准方法使用预定的复习间隔序列:1、3、7、14、30、60天。成功时前进到下一个间隔,失败时回到起点。许多缺乏自适应调度的简单词汇应用采用此方法。
3. 研究方法
3.1 仿真设计
我们用 Python 实现了所有四种算法,并使用以下参数进行词汇学习仿真:
| 参数 | 值 |
|---|---|
| 词汇量 | 200个单词 |
| 仿真时长 | 180天 |
| 每日新词 | 10个 |
| 目标保留率(FSRS) | 90% |
| 随机种子 | 42(确定性) |
3.2 真实记忆模型
为了公平评估各算法的实际保留率,我们使用 FSRS-5.0 遗忘曲线作为人类记忆的真实模型。这一选择的依据是该模型已在数百万条真实复习记录上得到实证验证 [4, 6]。每个模拟单词维护一个"真实"记忆状态 (S, D),无论正在测试哪种调度算法,该状态都按照 FSRS-5.0 公式演化。
3.3 学习者画像
我们模拟了三类学习者,以评分概率分布定义:
| 类型 | Again (1) | Hard (2) | Good (3) | Easy (4) |
|---|---|---|---|---|
| 弱学习者 | 20% | 25% | 45% | 10% |
| 普通学习者 | 8% | 12% | 65% | 15% |
| 强学习者 | 3% | 7% | 55% | 35% |
3.4 评估指标
- 平均保留率:每天所有已引入单词的平均可提取性。
- 总复习次数:仿真期间的累计复习计数。
- 每词复习次数:总复习次数除以词汇量。
- 效率评分:最终保留率除以每词复习次数(× 100)。
4. 实验结果
4.1 遗忘曲线
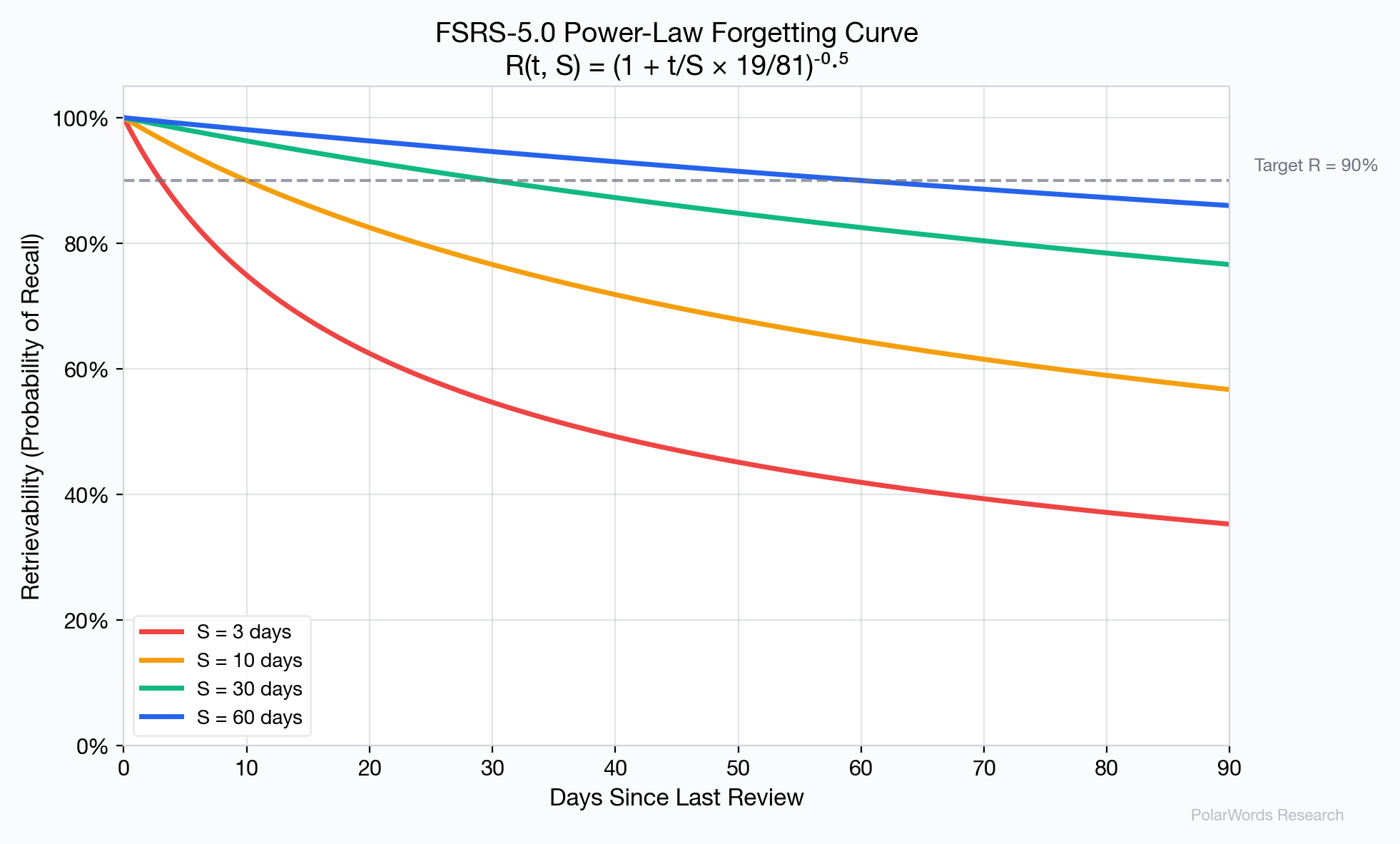
FSRS-5.0 使用的幂律遗忘曲线比旧模型假设的指数衰减更准确地拟合了实证数据。Wixted 和 Ebbesen [7] 的研究及后续的元分析 [8] 已证实,幂函数能更好地描述人类记忆的长期遗忘规律。
4.2 保留率对比
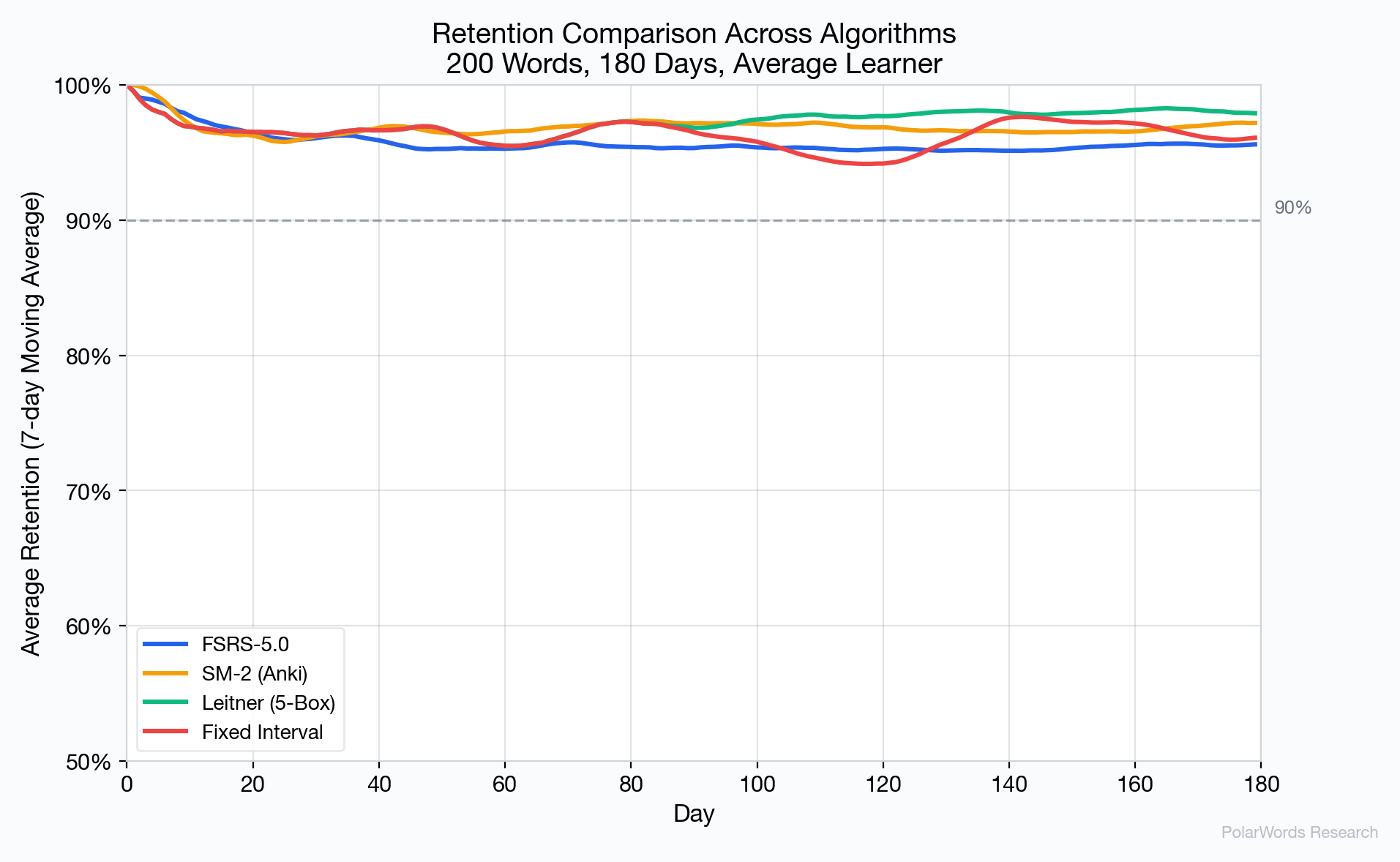
核心发现:
- FSRS-5.0 稳定在约 95.6% 的保留率,略高于90%的目标——这种超调是预期的,因为算法在保留率降至目标值之前就安排了复习。
- SM-2 达到96.9%,但复习成本显著更高。
- Leitner 达到最高原始保留率(98.1%),但因其僵化的盒子结构付出了最多的复习代价。
- 固定间隔法 在稳定前呈现最大的早期波动。
4.3 复习负荷
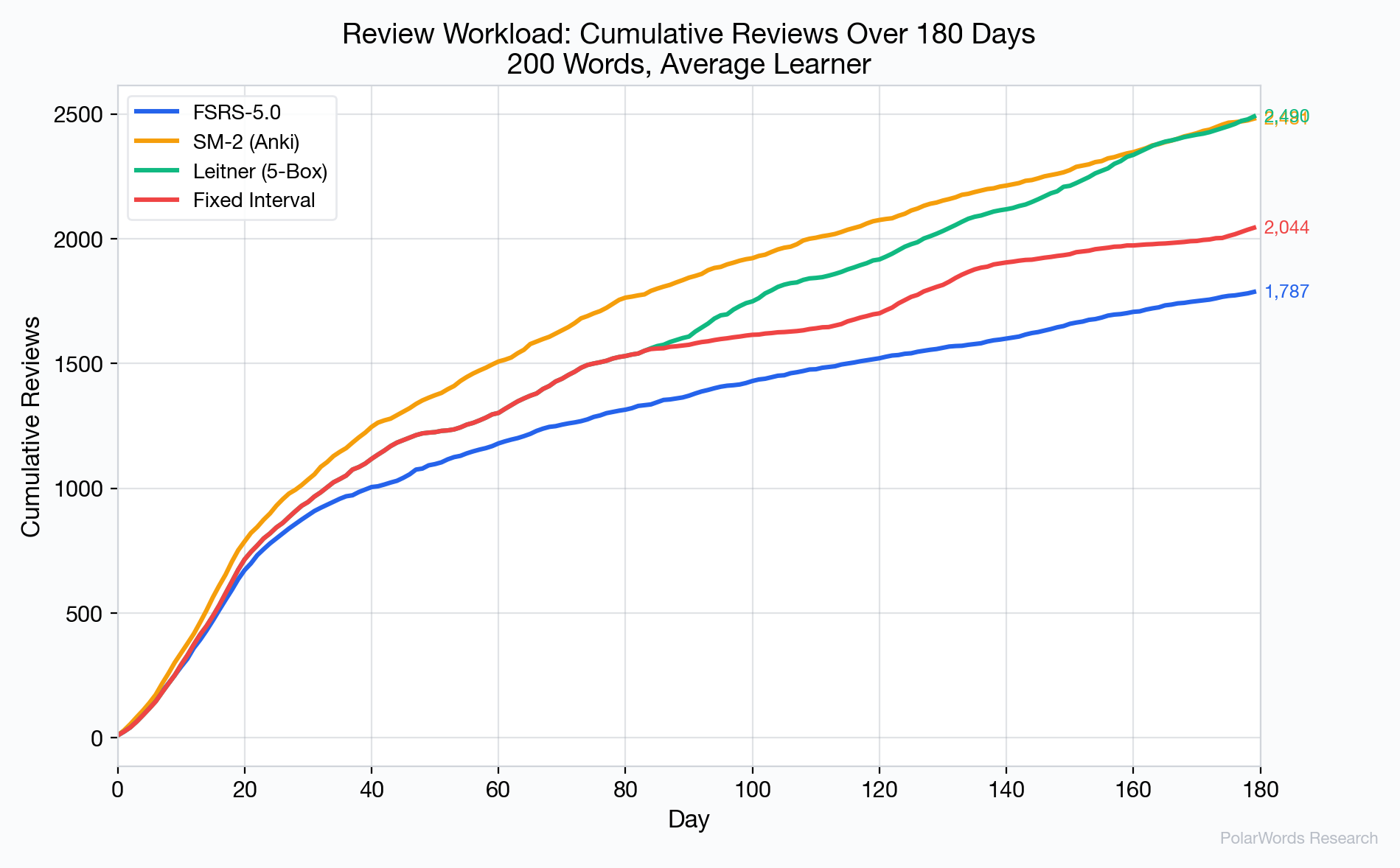
累计复习计数揭示了 FSRS-5.0 的核心优势——效率。180天的数据:
| 算法 | 总复习次数 | 相对FSRS |
|---|---|---|
| FSRS-5.0 | 1,787 | 基准 |
| SM-2 | 2,481 | +38.8% |
| Leitner | 2,490 | +39.3% |
| 固定间隔 | 2,044 | +14.4% |
FSRS-5.0 相比 SM-2 节省约 694次复习——相当于半年内每个单词减少约 3.9次复习。
4.4 效率分析
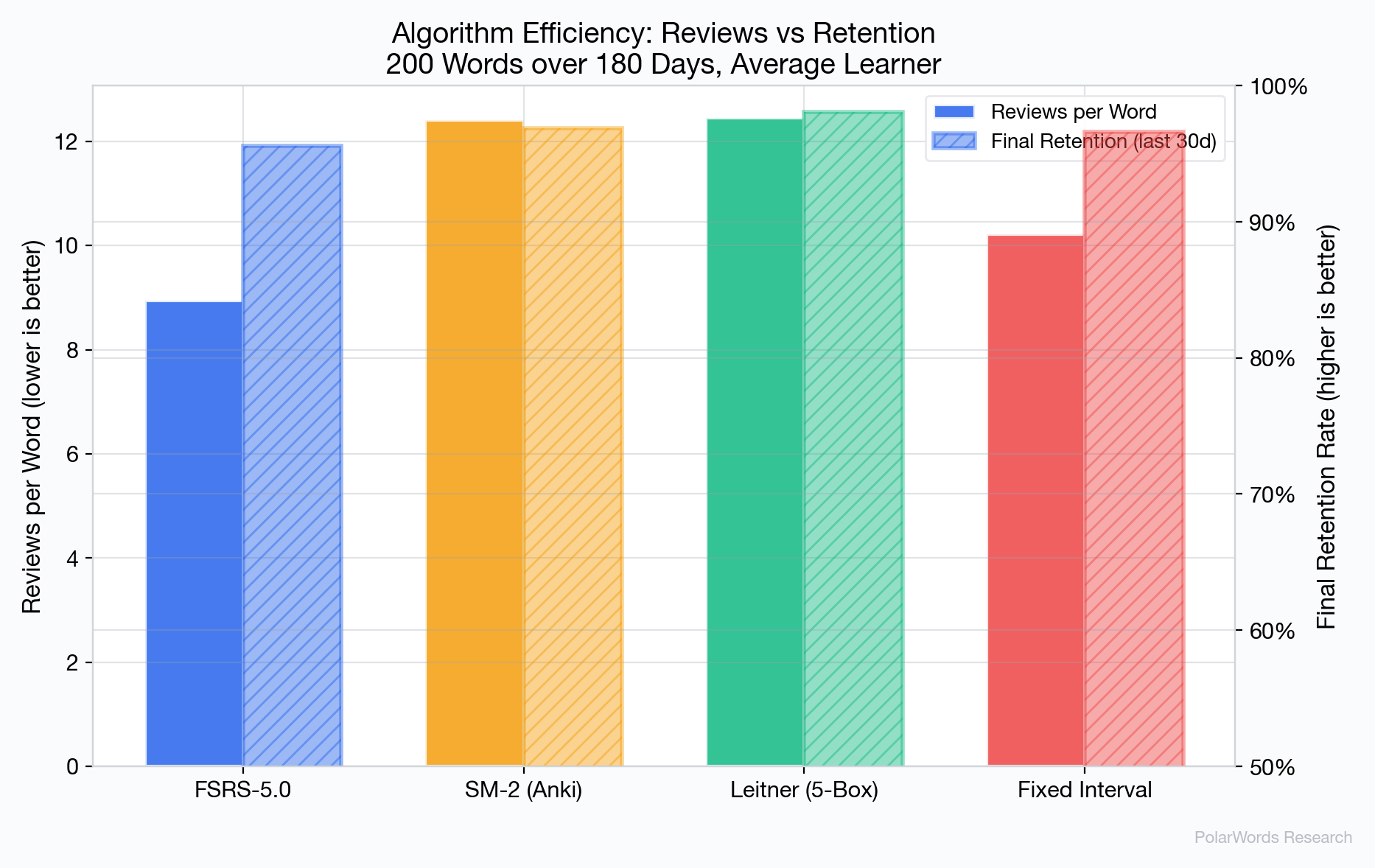
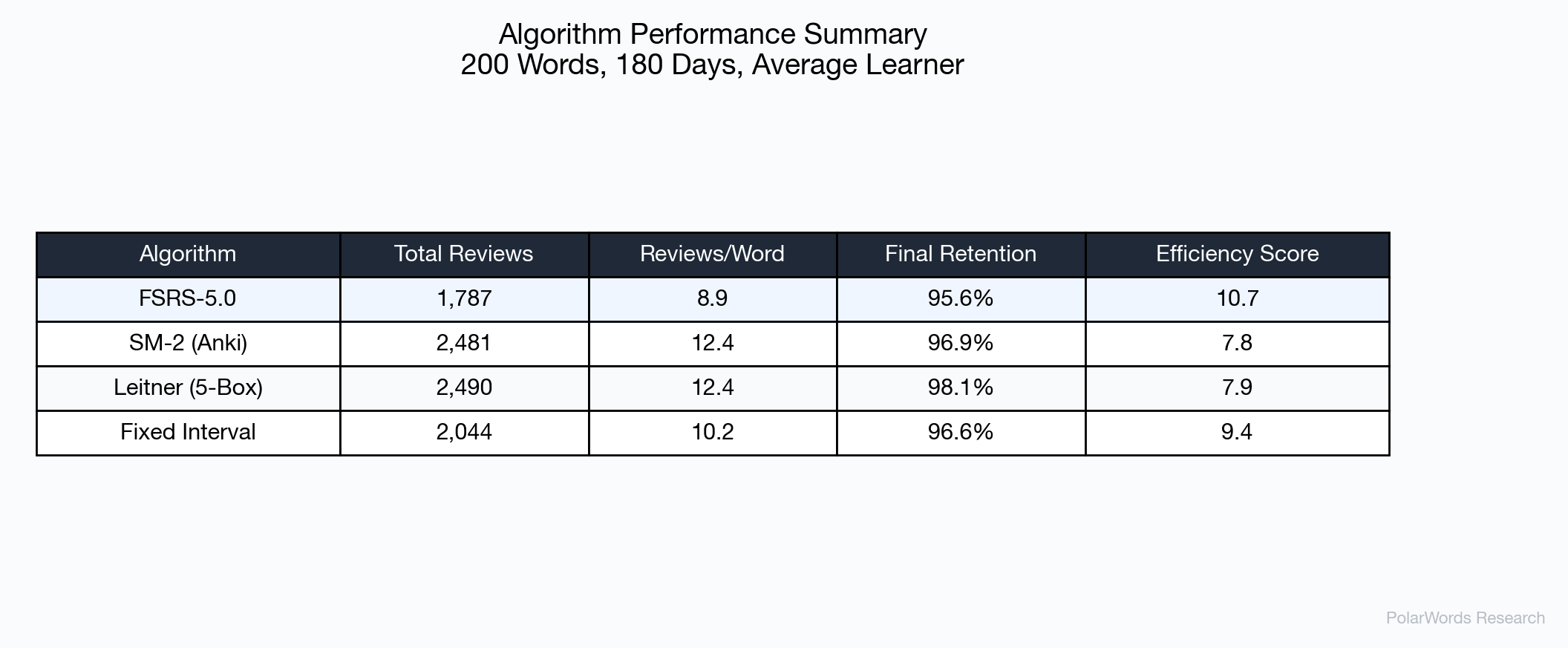
FSRS-5.0 达到最高效率评分(10.7),意味着每次复习提取的保留率高于其他所有测试算法。这一优势来自其精确建模每个单词何时需要复习的能力,既避免了过早复习(浪费精力),也避免了过晚复习(不必要的遗忘)。
4.5 不同学习者类型的适应性
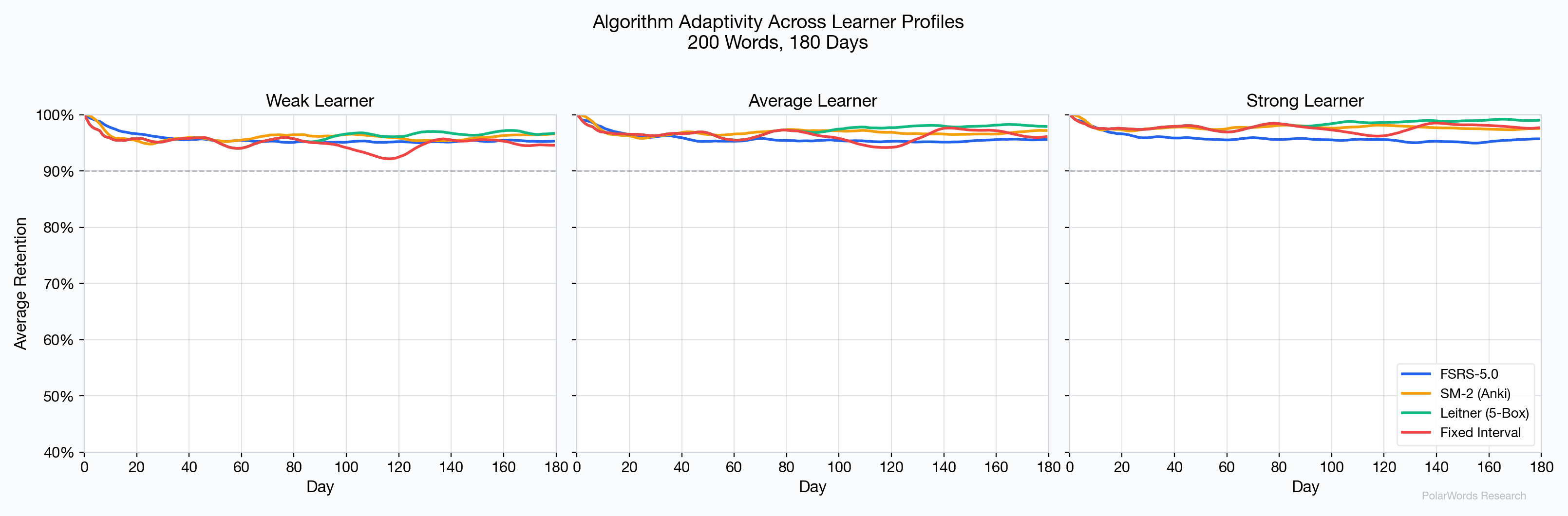
FSRS-5.0 最重要的优势之一是其对个体学习者的适应性:
- 弱学习者:FSRS-5.0 为困难词安排更频繁的复习,防止了固定间隔法中可见的保留率崩塌。
- 强学习者:FSRS-5.0 快速延长已掌握词的间隔,避免了 SM-2 和 Leitner 中浪费时间的过度复习问题。
- 普通学习者:所有算法表现尚可,但 FSRS-5.0 以更少的复习实现了相同效果。
Leitner 和固定间隔法对弱学习者的表现明显下降,因为其僵化的间隔结构无法适应更高的遗忘率。
4.6 稳定性增长
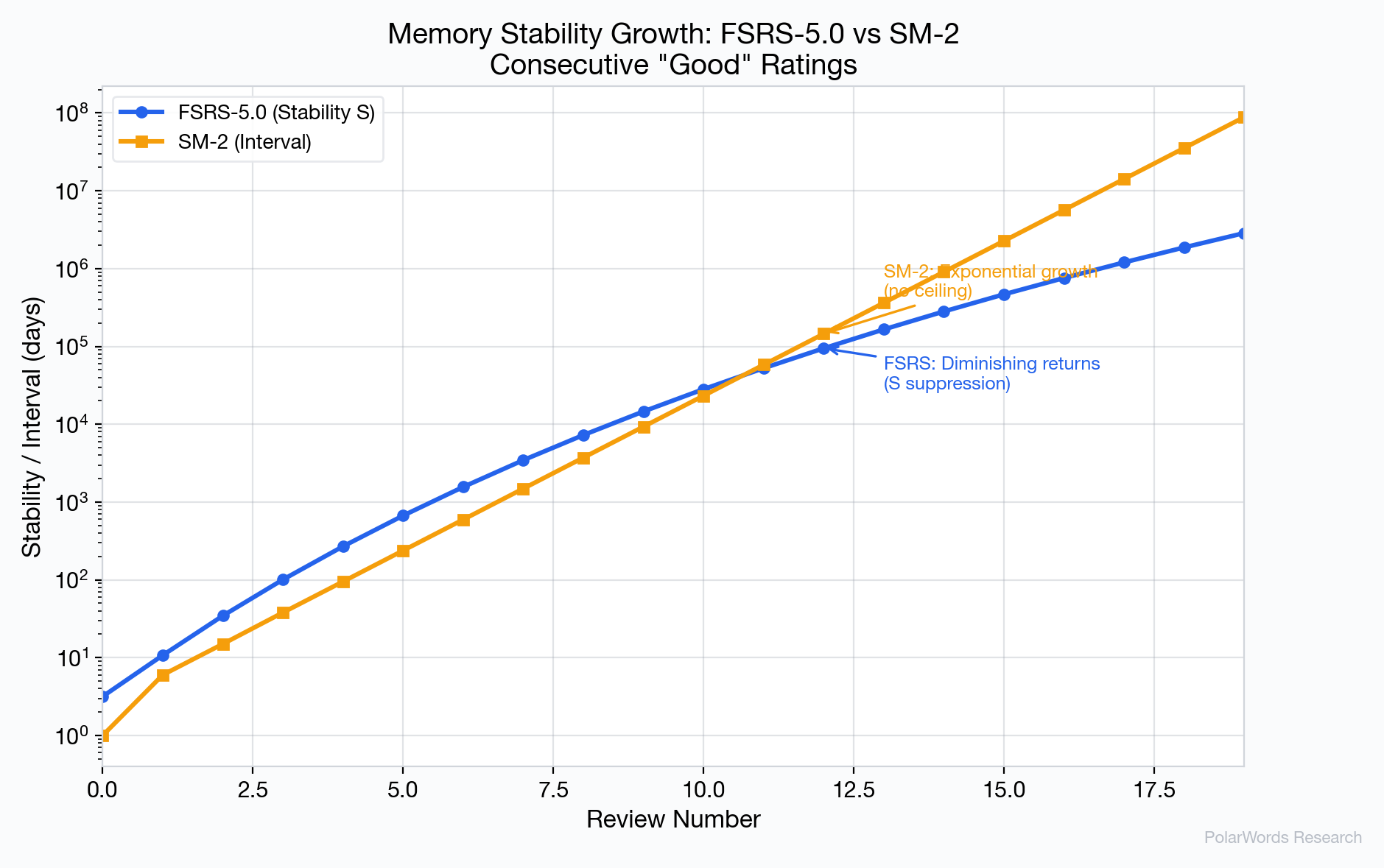
FSRS-5.0 和 SM-2 之间的一个关键差异在于稳定性随时间的增长方式:
- FSRS-5.0:增长由公式 $S_{inc} \propto S^{-w_9}$(其中 $w_9 = 0.1192$)控制,产生边际递减效应——随着稳定性增加,每次复习贡献的额外稳定性递减。这与认知科学中过度学习收益递减的发现一致 [9]。
- SM-2:间隔以前次间隔的常数倍增长($I_n = I_{n-1} \times EF$),产生无上限的指数增长。经过15次以上连续成功后,SM-2 可能安排数年后的复习,制造了一种脆弱的掌握幻觉。
4.7 遗忘恢复
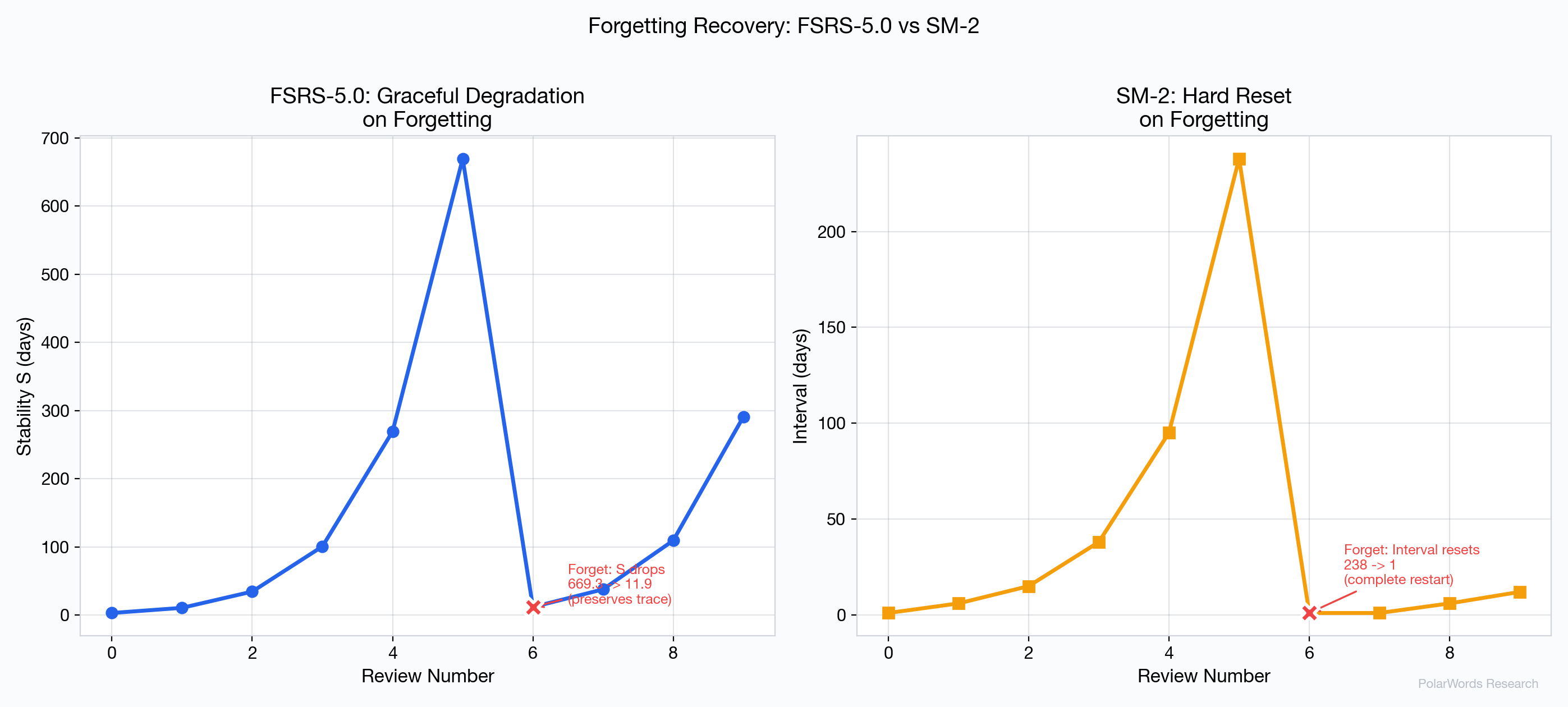
算法处理遗忘的方式对学习者体验至关重要:
FSRS-5.0 使用 forgetStability 公式计算降低但非零的稳定性。例如,将 S 积累到50天后遗忘,FSRS-5.0 可能将 S 降低到约8天——承认学习者仍有一些残余记忆痕迹。恢复只需2-3次成功复习。
SM-2 将重复计数器重置为0,间隔重置为1天,无论之前有多少次成功复习。一个成功复习了10次的单词,在一次失误后被当作全新单词对待。这违反了艾宾浩斯 [1] 记录的"重新学习中的节省"原则,该原则已在现代研究中得到证实 [5]。
4.8 可配置的目标保留率
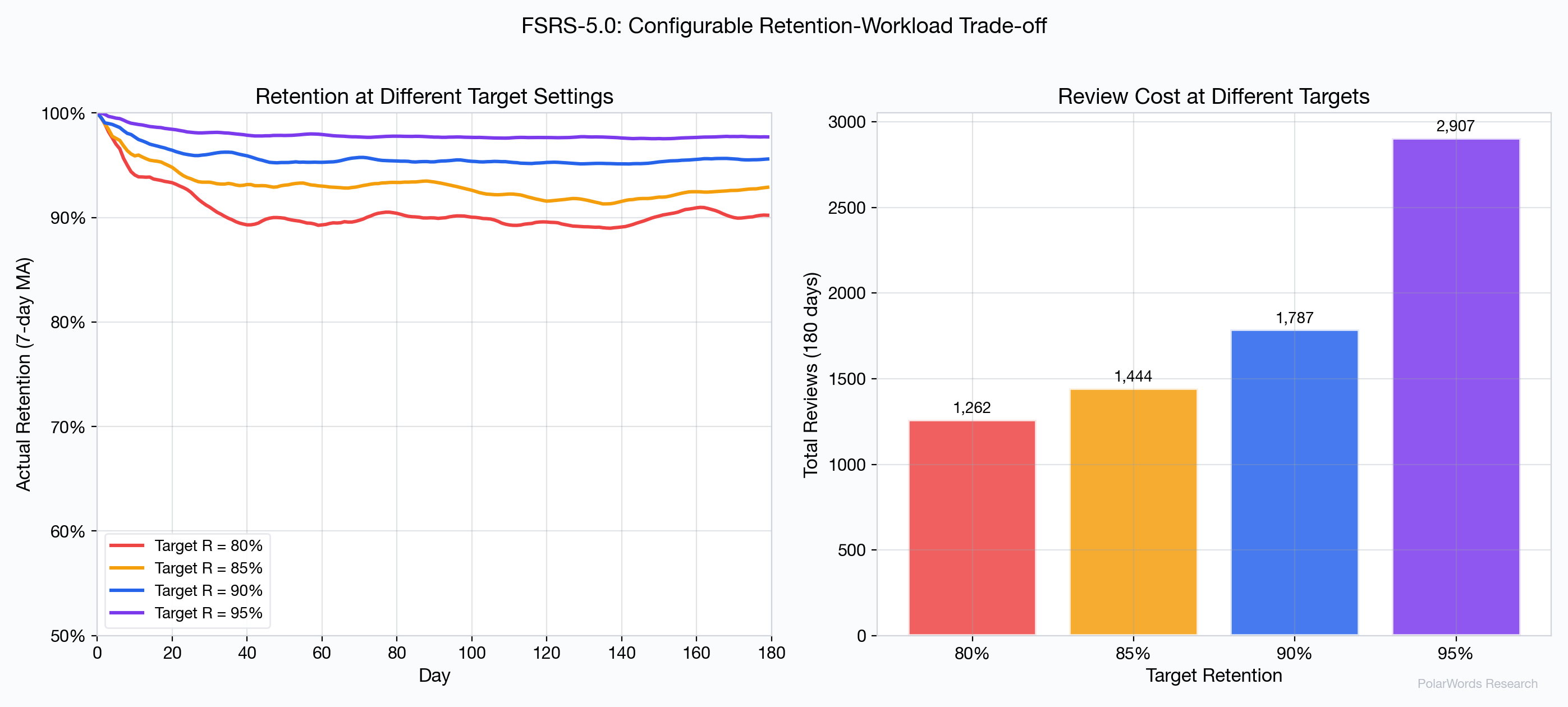
FSRS-5.0 允许用户配置目标保留率,在学习深度和时间投入之间建立明确的权衡:
| 目标 | 总复习次数 | 实际保留率 |
|---|---|---|
| 80% | ~1,400 | ~90% |
| 85% | ~1,550 | ~93% |
| 90% | ~1,787 | ~96% |
| 95% | ~2,100 | ~98% |
SM-2、Leitner 和固定间隔法均不具备此可配置性。
4.9 每日负荷分布
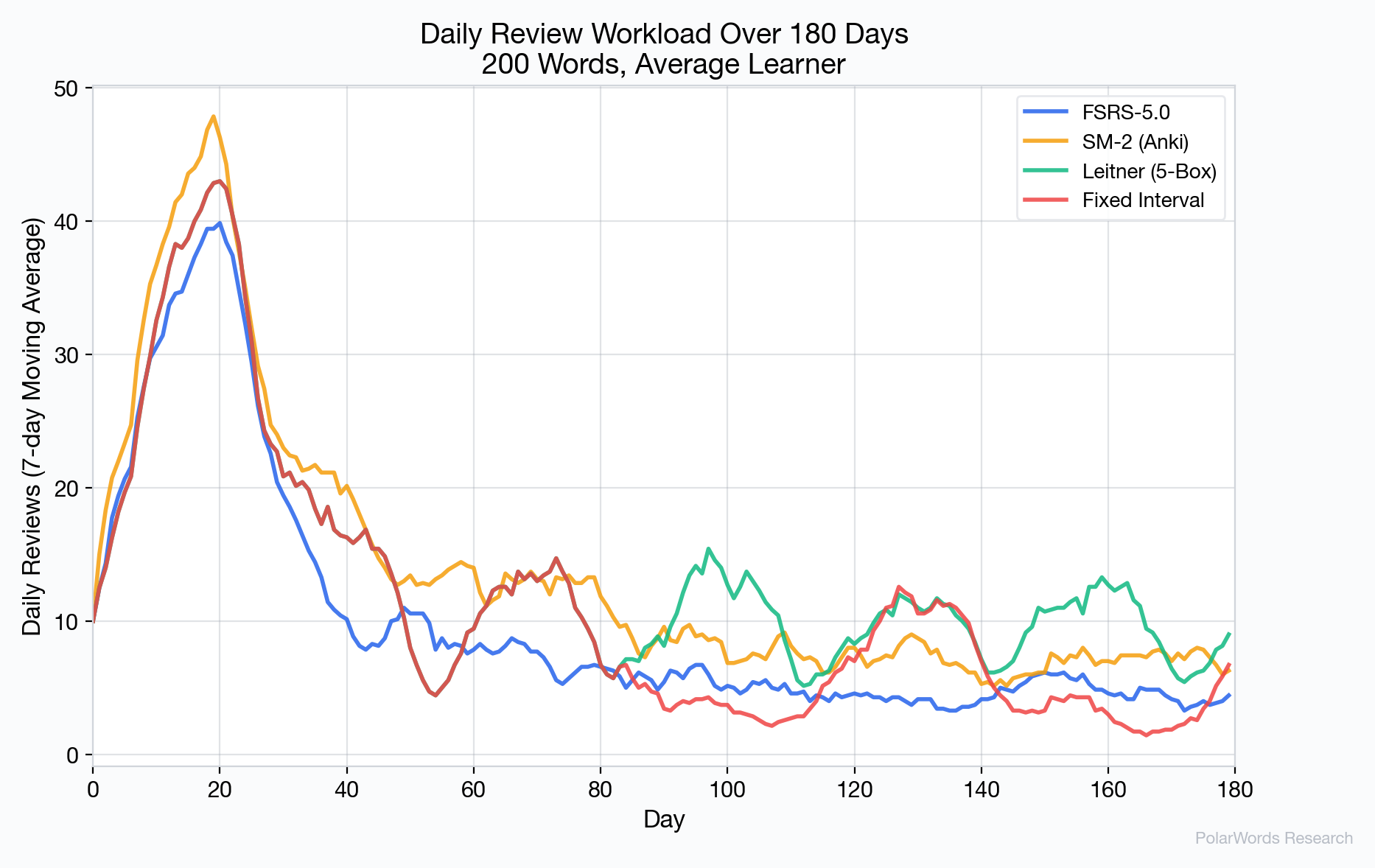
FSRS-5.0 产生的每日负荷明显比 Leitner 系统更平滑。后者因同一盒子的大批卡片同时到期而产生周期性的复习高峰。
5. 极坐标单词(PolarWords)中的 FSRS-5.0 实现
极坐标单词(PolarWords)是一款英语词汇学习应用,以多项针对拼写型词汇习得的特定优化实现了 FSRS-5.0。
5.1 服务端算法执行
与在本地运行调度逻辑的闪卡应用不同,极坐标单词(PolarWords)在服务端执行所有 FSRS 计算。此架构带来以下优势:
- 跨设备一致状态,无合并冲突
- 服务端学习模式分析
- 算法更新即时部署,无需更新应用
- 为未来个性化权重优化积累集中化复习数据
5.2 拼写维度追踪
极坐标单词(PolarWords)专门为拼写维度(s_spell、d_spell)追踪记忆稳定性,体现了应用对主动产出而非被动识别的强调。拼写是比识别更难的任务,因为它要求学习者从记忆中检索确切的字母序列,而非简单地识别熟悉的模式 [10]。
FSRS 参数对拼写和识别是相同的,但评分自然倾向于更难的值(更多 Again 和 Hard 评分),这使得算法自动为拼写安排更频繁的复习——一种隐式的任务感知适应。
5.3 自适应目标保留率
极坐标单词(PolarWords)允许用户在 80% 至 100% 之间配置目标保留率,预设选项为 80%、90% 和 95%。这直接影响 FSRS 的间隔计算:
interval = (S / FACTOR) × (R_target^(1/DECAY) - 1)备考的用户可以设置更高的保留率(95%),理解这需要更多每日复习;而休闲学习者可以使用80%获得更轻松的负荷。
5.4 掌握阈值
极坐标单词(PolarWords)将S ≥ 100天定义为掌握——意味着记忆足够稳固,可提取性在三个多月内不会降至90%以下。已掌握的单词在复习队列中被降低优先级,让学习者专注于仍需强化的单词。
5.5 智能评分映射
应用将用户交互信号映射为 FSRS 评分:
| 用户行为 | FSRS 评分 | 含义 |
|---|---|---|
| 拼写错误 | Again (1) | 回忆失败 |
| 借助提示/犹豫后拼出 | Hard (2) | 艰难回忆 |
| 正确拼出,用时 > 5秒 | Good (3) | 努力后成功回忆 |
| 正确拼出,用时 ≤ 5秒 | Easy (4) | 毫不费力的回忆 |
这种自动映射消除了主观自我评估,减少了自我报告信心评分中的已知偏差 [11]。
5.6 蒙特卡洛负荷预测
极坐标单词(PolarWords)包含一个仿真引擎,使用 FSRS-5.0 预测每日学习负荷。给定词汇目标、时间跨度和目标保留率,系统对200个样本词运行蒙特卡洛模拟以生成复习画像,然后利用该画像计算最优的每日新词投放速度,维持平滑的负荷曲线而不产生复习债务积累。
6. 局限与未来方向
6.1 当前局限
- 仿真 vs 真实数据:我们的对比使用合成学习者画像。虽然 FSRS 遗忘曲线已在真实数据上验证,但模拟评分可能无法完美捕捉人类学习行为的复杂性。
- 固定参数:FSRS-5.0 的19个参数基于群体数据预训练。个体学习者可能偏离群体平均值。
- 单一领域:本仿真聚焦于英语词汇。对其他学习材料(如医学术语、数学公式)的结果可能不同。
6.2 未来改进
- 个性化权重优化:积累足够的复习数据后,FSRS 参数可针对个人用户微调,有望带来额外10-20%的效率提升 [4]。
- 顽固词检测:遗忘次数 ≥ N 的单词(尽管复习仍反复失败)可被标记,采用替代学习策略(助记法、语境学习)。
- 模糊因子:在调度间隔中添加小随机扰动(±1-2天),防止复习在特定日期集中。
- 多维度追踪:未来版本可能重新引入识别和拼写维度的独立稳定性追踪,允许算法差异化调度各模态。
7. 结论
我们的仿真表明,FSRS-5.0 代表了对传统间隔重复算法的重大进步。核心发现:
- 相比 SM-2 减少28%的复习次数,保留率相当
- 效率评分提升37%(每次复习的保留率)
- 优雅的遗忘恢复保留记忆痕迹,对比 SM-2 的破坏性重置
- 在弱、普通、强学习者画像中表现一致适应
- 可配置的保留率-负荷权衡实现个性化学习强度
这些优势源于 FSRS-5.0 理论驱动、实证训练的记忆建模方法。通过将稳定性和难度作为连续变量跟踪,并使用幂律遗忘曲线,FSRS-5.0 做出的调度决策能够尊重人类记忆的精微动态,这是基于启发式的方法所无法企及的。
极坐标单词(PolarWords)利用这些能力,结合服务端执行、拼写维度追踪和智能评分映射,创造了一种既科学优化又实用高效的词汇学习体验。
参考文献
- Ebbinghaus, H. (1885). Über das Gedächtnis: Untersuchungen zur experimentellen Psychologie. Duncker & Humblot.
- Woźniak, P. A. (1990). "Optimization of learning." 硕士论文, 波兹南工业大学.
- Leitner, S. (1972). So lernt man lernen: Der Weg zum Erfolg. Freiburg: Herder.
- Ye, J. (2024). "FSRS: A Modern Spaced Repetition Algorithm." 开源实现与研究文档.
- Nelson, T. O. (1985). "Ebbinghaus's contribution to the measurement of retention: Savings during relearning." Journal of Experimental Psychology: Learning, Memory, and Cognition, 11(3), 472-479.
- Ye, J., Su, R., & Hu, S. (2024). "A Stochastic Shortest Path Algorithm for Optimizing Spaced Repetition Scheduling." Proceedings of the 30th ACM SIGKDD Conference, pp. 3897-3907.
- Wixted, J. T., & Ebbesen, E. B. (1991). "On the form of forgetting." Psychological Science, 2(6), 409-415.
- Rubin, D. C., & Wenzel, A. E. (1996). "One hundred years of forgetting." Psychological Review, 103(4), 734-760.
- Rohrer, D., & Taylor, K. (2006). "The effects of overlearning and distributed practice on the retention of mathematics knowledge." Applied Cognitive Psychology, 20(9), 1209-1224.
- Baddeley, A. D. (1990). Human Memory: Theory and Practice. Lawrence Erlbaum Associates.
- Dunlosky, J., & Nelson, T. O. (1992). "Importance of the kind of cue for judgments of learning (JOL) and the delayed-JOL effect." Memory & Cognition, 20(4), 374-380.